A Amazon Bedrock anunciou novos recursos de avaliação RAG e LLM-as-a-judge, simplificando o teste e o aprimoramento de aplicativos de IA generativa. As bases de conhecimento do Amazon Bedrock agora oferecem suporte à avaliação RAG, permitindo que você execute uma avaliação automática da base de conhecimento para avaliar e otimizar os aplicativos Retrieval Augmented Generation (RAG). Isso usa um modelo de linguagem grande (LLM) para calcular as métricas de avaliação, permitindo a comparação de diferentes configurações e ajustes para obter resultados ideais. A avaliação de modelo do Amazon Bedrock agora inclui o LLM-as-a-judge, permitindo o teste e a avaliação de outros modelos com qualidade semelhante à humana por uma fração do custo e do tempo. Esses recursos fornecem avaliação rápida e automatizada de aplicativos de IA, encurtando os ciclos de feedback e acelerando as melhorias. As avaliações analisam as dimensões da qualidade, como correção, utilidade e critérios de IA responsável, como recusa de resposta e nocividade. Os resultados fornecem explicações em linguagem natural para cada pontuação, normalizadas de 0 a 1 para facilitar a interpretação. As rubricas e os prompts do juiz são publicados na documentação para transparência.
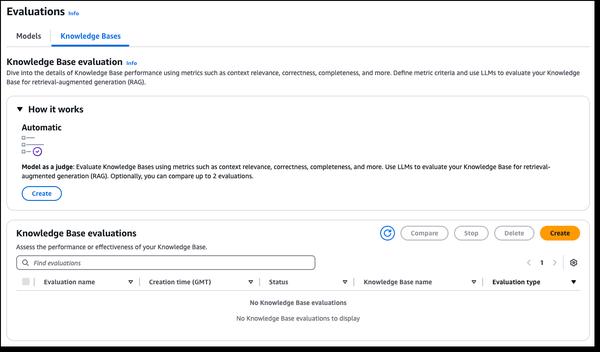
Novos recursos de avaliação RAG e LLM-as-a-judge no Amazon Bedrock
AWS