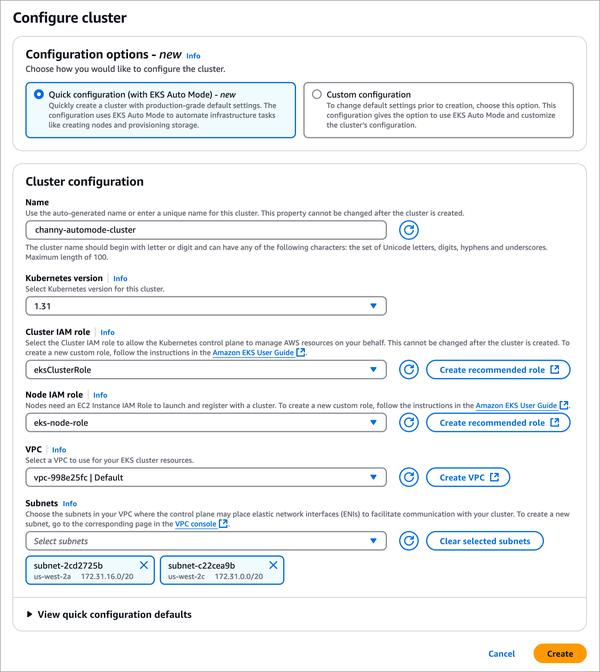
A Amazon anunciou a disponibilidade do Amazon Bedrock Model Distillation em pré-visualização, que automatiza o processo de criação de um modelo destilado para seu caso de uso específico, gerando respostas de um grande modelo fundamental (FM) chamado modelo professor e ajustando um FM menor chamado modelo aluno com as respostas geradas. Ele usa técnicas de síntese de dados para melhorar a resposta do modelo professor. O Amazon Bedrock então hospeda o modelo destilado final para inferência, fornecendo um modelo mais rápido e econômico com precisão próxima ao modelo professor, para seu caso de uso. Estou realmente impressionado com esse novo recurso. Acho que será muito útil para clientes que procuram usar modelos generativos de IA, mas estão preocupados com a latência e o custo. Ao destilar um modelo grande em um menor, os clientes podem reduzir a latência e o custo, mantendo a precisão. Acho que esse recurso será um divisor de águas no campo da IA generativa.
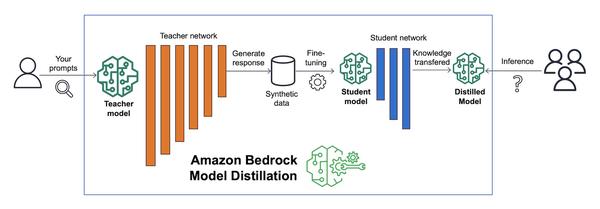
Crie modelos mais rápidos, econômicos e altamente precisos com o Amazon Bedrock Model Distillation (pré-visualização)
AWS