A Amazon anunciou a disponibilidade das novas instâncias Amazon EC2 Trn2 e Trn2 UltraServers, suas opções de computação EC2 mais poderosas para treinamento e inferência de aprendizado de máquina (ML). Alimentadas pela segunda geração de chips AWS Trainium (AWS Trainium2), as instâncias Trn2 são 4 vezes mais rápidas, têm 4 vezes mais largura de banda de memória e 3 vezes mais capacidade de memória do que as instâncias Trn1 de primeira geração. Elas oferecem um desempenho de preço de 30 a 40% melhor do que as instâncias EC2 P5e e P5en baseadas em GPU da geração atual. Cada instância Trn2 possui 16 chips Trainium2, 192 vCPUs, 2 TiB de memória e 3,2 Tbps de largura de banda de rede do Elastic Fabric Adapter (EFA) v3 com latência até 50% menor. Os Trn2 UltraServers, uma nova oferta, apresentam 64 chips Trainium2 conectados com uma interconexão NeuronLink de alta largura de banda e baixa latência, para desempenho máximo em modelos de base de ponta. Dezenas de milhares de chips Trainium já alimentam os serviços da Amazon e da AWS. Mais de 80.000 chips AWS Inferentia e Trainium1 deram suporte ao assistente de compras Rufus no Prime Day. Os chips Trainium2 alimentam as versões otimizadas para latência dos modelos Llama 3.1 405B e Claude 3.5 Haiku no Amazon Bedrock. As instâncias Trn2 estão disponíveis na região leste dos EUA (Ohio) e podem ser reservadas usando os Blocos de capacidade do Amazon EC2 para ML. Os desenvolvedores podem usar as AMI de aprendizado profundo da AWS, pré-configuradas com estruturas como PyTorch e JAX. Os aplicativos existentes do AWS Neuron SDK podem ser recompilados para Trn2. O SDK se integra ao JAX, PyTorch e bibliotecas como Hugging Face, PyTorch Lightning e NeMo. O Neuron inclui otimizações para treinamento e inferência distribuídos com NxD Training e NxD Inference e oferece suporte a OpenXLA, permitindo que os desenvolvedores PyTorch/XLA e JAX aproveitem as otimizações do compilador do Neuron.
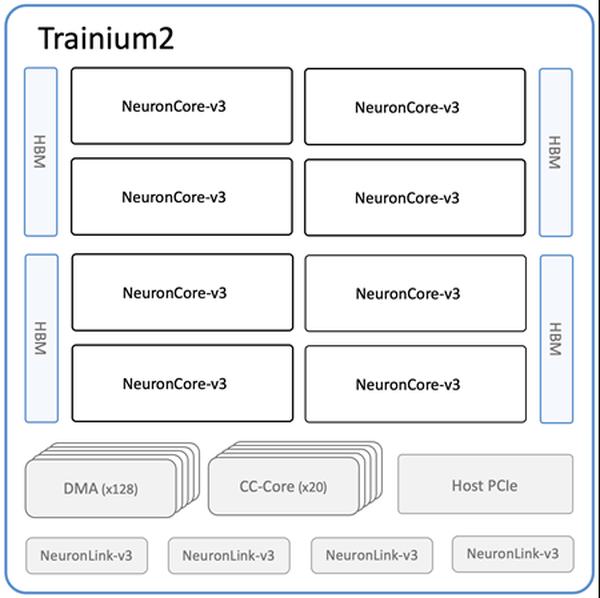
Instâncias Amazon EC2 Trn2 e Trn2 UltraServers agora disponíveis para treinamento e inferência de IA/ML
AWS